프로세스 간의 통신
- 서비스와 서비스간의 통신을 위해 인터페이스가 필요
- 인터페이스의 요구 방식 대로 커뮤니케이션
- 서버/클라이언트 아키텍처에서 HTTP 프로토콜을 이용하여 메소드 및 엔드포인트로 구성된 REST API를 이용하여 통신
동기/비동기
- HTTP 프로토콜은 기본적으로 TCP or UDP 연결을 만든다 -> 요청에 따라 즉시 응답이 오는 형태이므로 동기적 응답
- 비동기 서비스의 작업은 단방향 알림으로 푸쉬알림의 예가 있음
1:1 및 다대다 통신
- 뉴스에 대한 구독 형식 서비스는 1:1이 아닌 1대다 커뮤니케이션 방식을 취합니다
- HTTP는 1:1 통신이다 -> 여러 클라이언트에게 동시에 응답을 전달하지 않음
-> 여러번의 1:1 커뮤니케이션임
데이터 교환 포맷 JSON
- JSON (JavaScript Object Notation) 데이터 교환을 위한 객체 형태의 포맷

- 서로 데이터를 송수신 하려면 같은 프로그램을 사용하거나 문자열처럼 범용적으로 읽을 수 있는 형태여야함
* JSON을 객체 형태로 변환
=> JSON.stringify : Object type 을 JSON으로 변환함 // 직렬화 (serialize) 라고도 함
=> JSON.parse : JSON을 Object type으로 변환함 // 역직렬화 (deserialize) 라고도 함
- stringify 를 통한 직렬화 (객체를 직렬화하여 문자열을 누군가에게 객체의 내용을 보냄)
let transferableMessage = JSON.stringify(message)
console.log(transferableMessage) // `{"sender":"김일등","receiver":"박이등","message":"이등아 오늘 저녁 같이 먹을래?","createdAt":"2021-01-12 10:10:10"}`
console.log(typeof(transferableMessage)) // `string`- parse 를 통한 string 타입의 메시지를 객체 형태로 변환
let packet = `{"sender":"김코딩","receiver":"박해커","message":"해커야 오늘 저녁 같이 먹을래?","createdAt":"2021-01-12 10:10:10"}`
let obj = JSON.parse(packet)
console.log(obj)
/*
* {
* sender: "김코딩",
* receiver: "박해커",
* message: "해커야 오늘 저녁 같이 먹을래?",
* createdAt: "2021-01-12 10:10:10"
* }
*/
console.log(typeof(obj))
// `object`
JSON 기본 규칙
- JavaScript와 미묘하게 다른 규칙이 있음
- JSON은 키와 값 사이, 그리고 키-값 쌍 사이에는 공백이 있어서는 안됨

??? JSON이 XML 보다 유리한 점
- 파싱의 편의성 = 객체나 다중배열로 즉각 변환 가능
- 파싱의 성능이 높음
- 더 적은 데이터의 양
- 더 높은 처리 성능
동기식 요청/응답 통신 REST
REST 란?
- HTTP로 소통하는 프로세스 간 통신 규약
- REST API = 웹에서 사용되는 데이터나 자원(Resource)을 HTTP URI로 표현하고 HTTP 프로토콜을 통해 요청과 응답을 정의하는 방식
- HTTP의 Body 부분을 JSON 형태로 다루는 것이 보통이며 content-Type의 값(MIME 타입)은 applicaation/json 으로 설정함
REST 장점
- 포스트맨, curl 등의 도구를 사용해 간편하게 테스트 가능
- 요청/응답 통신을 직접 지원함
- 시스템 아키텍처가 단순함
REST 단점
- 요청/응답만 지원함
- 메시지를 주고받기 위해서 클라이언트와 서버 프로세스가 둘다 실행중 이어야함
- 요청 한번으로 여러 리소스를 조회하기 어려움
- 메소드만으로 한번의 요청을 통해 이루어지는 다양한 작업들을 대표하기 어려움
메시지 브로커를 이용한 비동기식 통신
비동기식 방식으로 통신 시 수신자가 메시지를 받기 전에 누군가는 메시지를 보관해놓아야함
=> 메시지 브로커 (메시지 큐)
메시지 브로커가 필요한 이유

느슨한 결합에서의 장점으로 한 시스템의 상태가 다른 시스템에 영향을 주지 않도록 한다
Server 1 이 DB2 로 가는 도중 Server 2 가 고장이 나더라도 메시지 브로커가 메시지를 보관해놓기 때문에 데이터가 유실되지 않음

메시지 브로커 특징
- 프로그램 간의 직접 연결 없음
=> 소비자 프로세스가 죽어도 생산자는 메시지를 보낼 수 있음
=> 생산자 프로세스가 죽어도 소비자는 메시지를 수신할 수 있음
- 메시지 브로커에 있는 메시지는 소비자(수신)가 꺼낼 때까지 안전하게 보관된다
=> 프로세스가 죽어있어도 메시지를 소비하기 전까지 사라지지 않음
=> 프로그램간 통신은 시간과 독립적
- 통신이 이벤트에 의해 구동될 수 있음
=> 큐의 상태에 따라 프로그램 제어 가능
=> 메시지가 큐에 도착하는 순간 프로그램을 시작하거나 할 수 있음
- 확장에 용이함
=> 메시지 브로커는 여러 큐를 만들거나 수평적으로 확장하여 메시지 부하 증가를 처리할 수 있음
메시지 브로커 단점
- 프로세스 간 직접 연결에 비해 아키텍처가 복잡함
CQRS 란?
- Command Query Responsibility Segregation(명령과 조회의 책임 분리)
- 명령을 처리하는 책임과 조회를 처리하는 책임을 분리하는 것
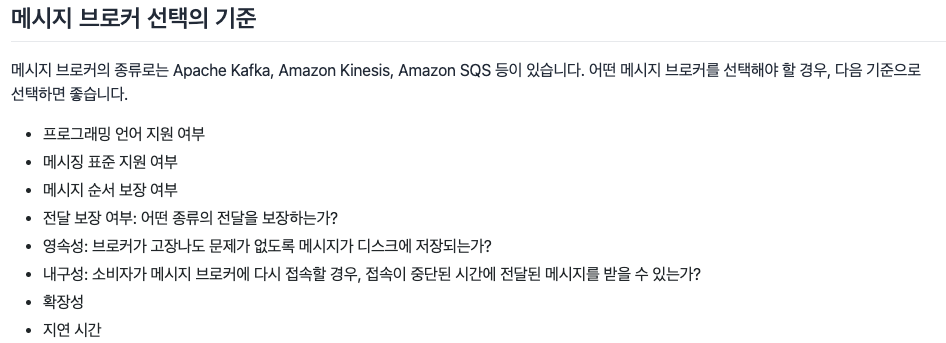
Q1. 메시지 서비스로는 대표적으로 Apache Kafka와 Amazon SQS, Amazon Kinesis가 있습니다. 각각은 어떤 차이가 있나요?
Kafka 란?
- 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼
- 대규모 데이터 동시 이동 가능
- 높은 처리량과 확장성이 반드시 필요한 활용 사례를 지원
- 초당 수백만 개의 데이터 포인트를 처리할 수 있어 빅데이터 쪽에 매우 적합 (사물인터넷 IoT 데이터 처리 활용에 사용되기도 함)
https://www.redhat.com/ko/topics/integration/what-is-apache-kafka
Amazon SQS 란?
- 내구력이 있고 가용성이 뛰어난 보안 호스팅 대기열을 제공
- 대기열에 메시지를 보내고 받을 수 있는 사용자 제어 가능 (보안성)
- 메시지를 안전하게 보관하기 위해 메시지를 여러 서버에 저장함 (내구성)
- 중복 인프라를 사용하여 고도의 동시 액세스와 메시지 생성 및 사용을 위한 고가용성을 제공함 (가용성)
- 여러 생산자가 동시에 메시지를 보내고 여러 소비자가 메시지를 받을 수 있음 (안정성)
- Kafka 만큼 빠르지 않으므로 작업 부하가 큰 워크로드에 적합하지 않음
- 초당 이벤트 수가 많지 않은 이벤트에 훨씬 적합함
https://docs.aws.amazon.com/ko_kr/AWSSimpleQueueService/latest/SQSDeveloperGuide/welcome.html
Amazon Kinesis
- 실시간 스트리밍 데이터를 손쉽게 수집, 처리 및 분석 가능
- 모든 규모의 스트리밍 데이터를 비용 효율적으로 처리할 수 있음
- Kafka 나 Kinesis 둘다 데이터 파이프 라인이 목적이며 데이터 이동 간 Seamless, Real-time 효익 달성에 초점이 맞춰져있음
https://aws.amazon.com/ko/kinesis/
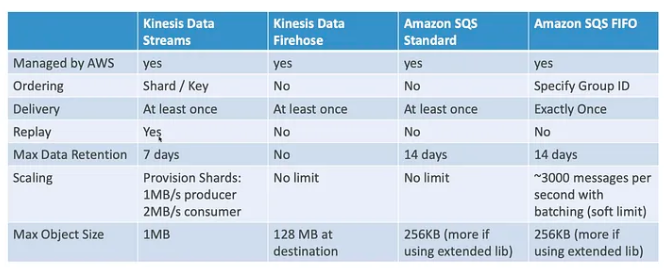
Q1-1. RabbitMQ와 Kafka 비교
RabbitMQ란?
- 메시지 브로커의 구현체
- 메시지 큐잉 방식 지원
- 여러개의 생산자와 소비자를 사용할 수 있으며 여러개의 생산자가 Message Exchange에 메시지를 보내며 정해진 규칙에 따라서 큐에 routing 이 되고, 소비자들이 메시지를 처리함
- message exchange를 사용한 pub/sub 방식도 구현
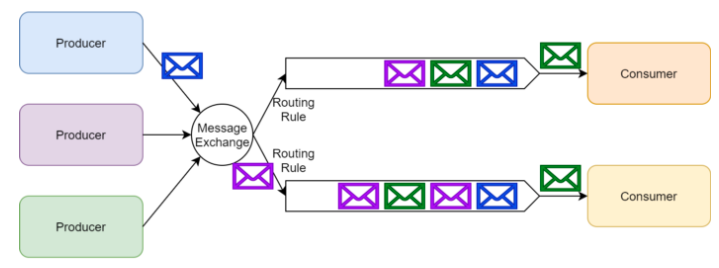
RabbitMQ와 Kafka 비교
- 동작 아키텍처
| Kafka | RabbitMQ | |
| 동작아키텍처 | Consumer -> broker -> partition -> Consumer |
Consumer-> Exchange -> binding rules -> queue -> producer |
| 성능 | 순차적인 disk I/O 방식을 통해 성능 향상한다. 적은 비용으로 많은 데이터 유지, 1초에 수백만개의 메세지 처리 가능하다. | 큐가 비어있을 때만 성능이 빠름, 1초에 수백만개의 메세지 처리 가능하지만 자원이 더 필요하다. |
| 메시지 보장 순서 | 같은 토픽 파티션으로 보내진 메세지는 순서대로 처리됨을 보장. 하지만 같은 토픽 내에 여러개의 파티션 사이에서 처리 순서는 보장하지 않는다. | 메세지 소비자가 하나라면, 메시지 순서를 보장한다. 그러나 메시지를 읽는 여러 소비자가 있으면 메시지 처리 순서에 대해 보장할 수 없다. |
| 라우팅 기능 | consumer가 polling 이전에, 토픽에서 메세지를 필터링을 할 수 없다. consumer는 예외없이 파티션의 모든 메세지를 수신해야만 한다. | opic exchange를 통해 헤더에 routing_key라는 값으로 라우팅 가능하다. 또한, header exchange를 사용해 임의의 메시지 헤더를 기반으로 라우팅. 최종적으로 consumer는 받고싶은 메세지의 종류만 수신 가능하다. |
| 지연메시지 | 토픽에 메세지가 도착하면 바로 파티션에 전달해서, consumer가 바로 소비할 수 있도록 한다. 파티션은 append-only 이기 때문에, 메세지 시간을 조작할 수 없으며 어플리케이션 수준에서 구현해야 한다. | procuer는 message exchange에서 큐에 전송되는 메세지 시간을 정할 수 있다. |
| 메시지 보유 및 삭제 | 토픽에 설정된 타임아웃 시간까지 모든 메세지가 저장됨, 카프카의 성능이 저장소 크기와 상관이 없으므로, 이론상으로 성능 영향없이 무한대로 메세지를 저장할 수 있다. | consumer가 메시지를 소비하자마자, ACK 메세지를 보내고 메세지 삭제, NACK 가 수신되면, 메세지는 다시 큐에 보내진다. message broker 설계 방식이므로 이 방식이 변경될 수 없다. |
| Fault 삭제 | 소비자가 특정 메세지를 처리하고 재시도할 수없다면, 다른 소비자들이 메세지를 처리할 수 있음 특정 소비자가 특정 메시지를 재시도하는 동안 전체 메시지 처리가 중단되지 않는다. 결과적으로 메시지 소비자는 전체 시스템에 영향을 주지 않고 원하는 만큼 메시지를 동기적으로 재시도한다. |
fault 처리 메커니즘을 제공하지 않는다. 어플리케이션 수준에서 메세지 재시도 메커니즘을 구현해야 한다. 만약에 소비자가 특정 메세지를 다시 시도한다면, 같은 파티션에 있는 다른 메세지들은 처리될 수 없다. 왜냐하면 소비자가 메세지 순서를 바꿀 수 없기 때문이다.(파티션은 append-only라는 특징을 기억) |
*RabbitMQ
1. 유연한 라우팅 규칙 적용 가능
2. 메시지 전송 타이밍 제어(메시지 만료 또는 메시지 지연 제어)
3. 소비자가 메시지 처리에 실패할 가능성이 더 높은 경우 고급 오류 처리 기능
4. 단순하게 소비자 기능 구현 가능
*Kafka
1. 엄격한 메세지 순서관리
2. 과거 메시지 재생 가능성을 포함하여 장기간 메시지 보존
3. 기존 솔루션으로는 충분하지 않는 대규모 구조
Q2. 웹 서비스에서 메시지 브로커(메시지 큐)를 이용해 비동기적인 방법이 활용되는 사례를 하나 이상 찾아보고, 어떻게 활용되는지 설명하세요.
ZUM.com
- 개선 전 서버에서 30초 주기로 뉴스 API 를 호출하여 뉴스 데이터를 폴링함 - 뉴스기사가 편집되지 않은 상태에서 불필요한 API 호출
- 뉴스기사가 편집되는 순간 메시지 브로커에 뉴스 기사 콘텐츠의 JSON을 전달함
- 메인에서 뉴스기사 컨텐츠를 실시간으로 구독&리스닝 하는 순간 서버에서 바로 적용함
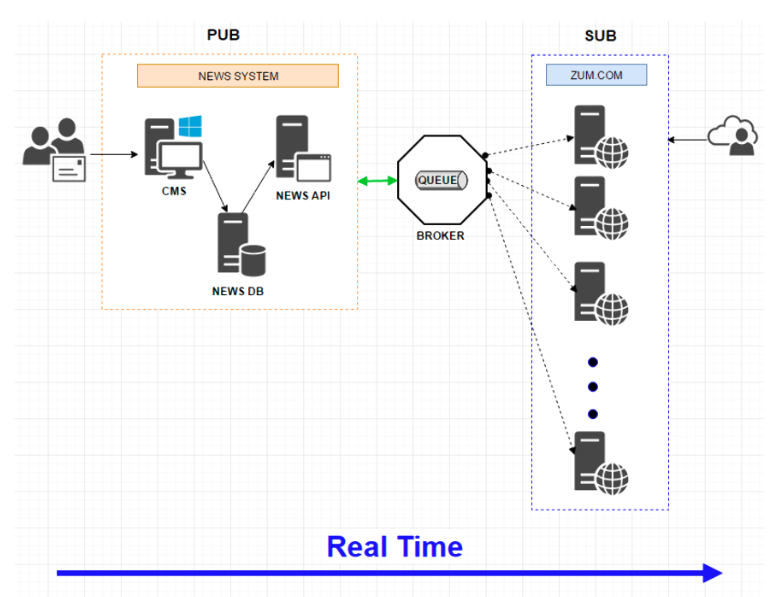
https://www.theteams.kr/teams/6045/post/69809
SPRING CLOUD STREAM, MQ 도입 사례 - 1 by 줌인터넷
SPRING CLOUD STREAM, MQ(Message Queuing) 도입 사례를 공유합니다. 좋은 의견 있으시면 꼭 말씀 부탁드리겠습니다. 글의 목차입니다. 도입 배경 관련 연구 RabbitMQ 따라잡기 Spring Cloud Stream
www.theteams.kr
'DevOps > DevOps' 카테고리의 다른 글
| 도메인 주도 설계 (DDD, Domain-Driven Design, 분산화 응용 프로그램 설계, 마이크로서비스, miro) (1) | 2023.02.16 |
|---|---|
| 독립적 서비스 구성 - AWS Lambda, API Gateway (0) | 2023.02.02 |
| 마이크로서비스 란? (구조 및 특징, 아키텍처 구현, 서버리스) (2) | 2023.01.30 |
| [Mac OS]Mac OS Proxy 서버 구동 (nginx) (0) | 2022.12.30 |
| MLOps 란? (DevOps 와 비교) (0) | 2022.12.21 |